統計モデルを作製するアルゴリズムの評価
統計モデルを作製する(学習する)アルゴリズムの良し悪しを測る指標としてバイアス (Bias)とバリアンス (Variance)がある。参考ページにも記載されているが、”モデルそのものの性能” を評価するための指標ではないことに注意する。
以下の図に示すように、モデル精度の悪さをバイアス、モデル作製の不安定さ(再現性の悪さ)をバリアンスと定義する。
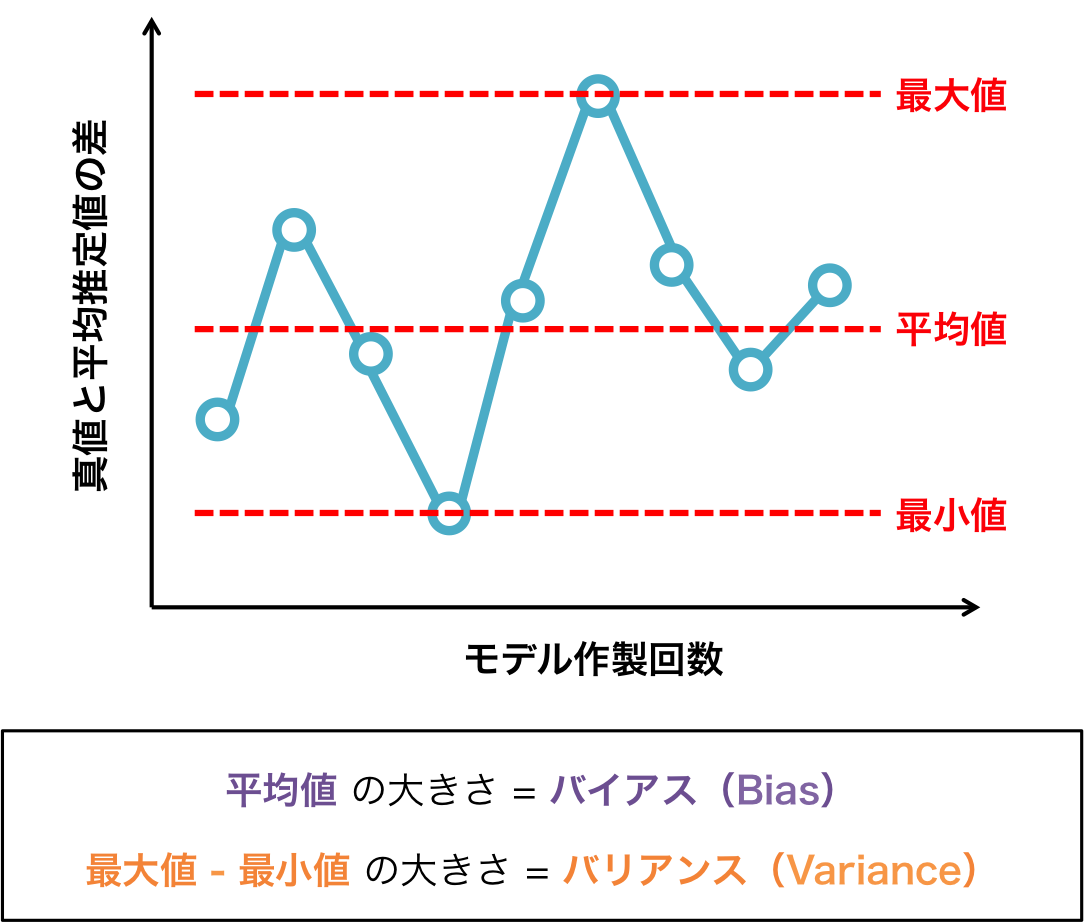
理想的なモデル作製アルゴリズムは、低いバイアス・低バリアンスなもの。
バイアスとバリアンスはトレードオフ
直感的には、
- モデルが単純
⇒ 性能は良くないが、教師データに対して安定
⇒ 高バイアス・低バリアンス - モデルが複雑
⇒ 性能は良いが、教師データに対して不安定(過学習など)
⇒ 低バイアス・高バリアンス
であるため、両者はトレードオフの関係にあると言える。回帰モデルの正則化手法と絡めて考えると、
- L1正則化(LASSO)
⇒ 一部の入力変数を用いてモデルを構築、入力変数の数を制限
⇒ モデルが単純
⇒ 高バイアス・低バリアンス - L2正則化(Ridge回帰)
⇒ 全ての入力変数を用いてモデルを構築、重みの大きさを制限
⇒ モデルが複雑
⇒ 低バイアス・高バリアンス
となり、バランスの良いモデル作製のために両者を組み合わせた Elastic Net が使われるようになっている。
コメントを残す